

Your company has delivered hundreds of projects. Different industries, different challenges, different outcomes. Every single one of them is proof that you can do the job.
But when a new opportunity lands and your sales team needs to find the three most relevant past projects to strengthen the pitch — what happens?
They email around. They dig through folders. They open dozens of PDFs hoping to find the right one. They ask the person who’s been here the longest. And half the time, they pitch with whatever they can find in 30 minutes, not what would actually win the deal.
That’s not a sales problem. It’s a knowledge retrieval problem. And it’s costing you deals.
The Hidden Cost of Not Finding What You Already Know
McKinsey found that employees waste 1.8 hours every day — nearly a quarter of the working week — just searching for information. IDC puts it even higher: 2.5 hours per day, roughly 30% of the workday, lost to hunting for things that already exist somewhere in the business.
For a sales team, that time is directly tied to revenue. Reps spend only 30% of their time actually selling. The rest gets eaten by admin, internal meetings, and — you guessed it — searching for the right documents to support a pitch.
Now multiply that across every deal, every week, every quarter. For a team of 20, that’s thousands of hours a year spent looking for information instead of closing.
The worst part? The information exists. It’s sitting in project reports, proposals, case studies, and delivery summaries across your shared drives. You’ve already done the work. You’ve already proved you can deliver. Your team just can’t find it fast enough when it matters.
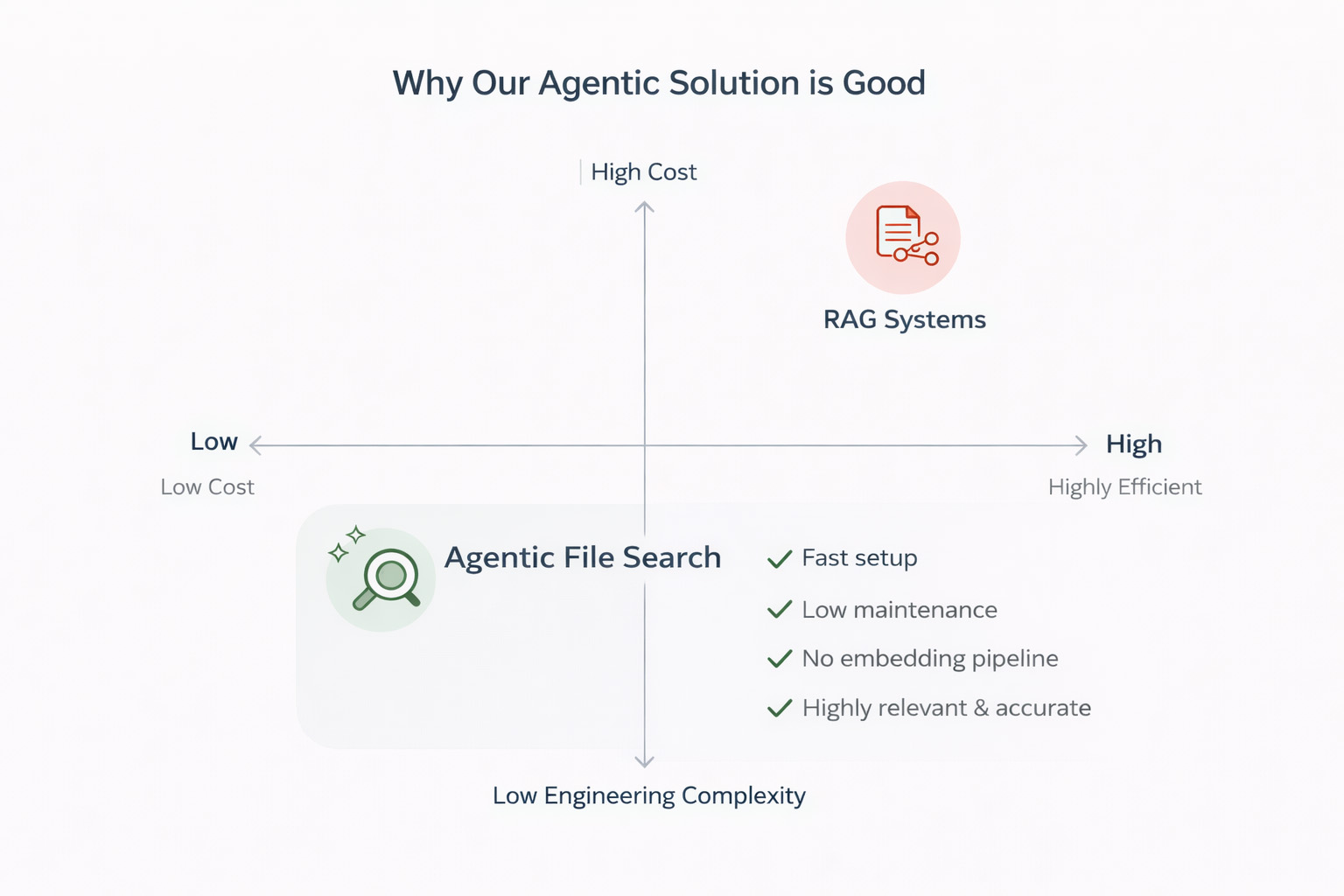
Why We Didn’t Build a RAG System
The obvious answer in 2026 is to throw RAG at it. Retrieval Augmented Generation — the standard approach where you embed all your documents into a vector database and let an AI search through them semantically.
On paper, it sounds perfect. In practice, it’s a nightmare for most businesses.
RAG systems break at scale because similarity search becomes noisy and imprecise as your document library grows. Chunks that are thematically similar but actually irrelevant get surfaced. The system retrieves confidently wrong answers and presents them as fact. And the effort to build, tune, and maintain a production-grade RAG pipeline? You’re looking at months of engineering work, constant reindexing, and an ongoing governance headache.
Most organisations can build a RAG proof of concept. Very few can run one reliably in production. The gap has nothing to do with model quality — it’s a systems architecture problem that most SMEs simply don’t have the resources to solve.
We needed something that worked in days, not months. Something that didn’t require vector databases, embedding pipelines, or a team of ML engineers to maintain.
The Agentic Approach: Let the AI Read Like a Human
So we took a different approach.
Instead of pre-processing every document into embeddings and hoping the right chunks surface, we built an agentic file search tool. The concept is simple: give the AI agent access to the documents and let it read, reason, and navigate them the way a human would — just dramatically faster.
When a sales rep has a new opportunity, they describe it in plain language. The agent then searches across hundreds of project documents — PDFs, proposals, delivery reports, case studies — looking for projects with similar industries, challenges, technologies, or outcomes. It reads the actual content, understands context, and returns the most relevant matches with a clear explanation of why they’re relevant.
No embeddings. No vector database. No six-month build. No hallucinated answers stitched together from document fragments.
The agent doesn’t guess at relevance based on mathematical similarity. It reads and reasons. That’s the difference.
What Changed for the Sales Team
The impact was immediate.
Before the tool, preparing for a pitch meant hours of digging through folders, asking colleagues, and settling for “close enough” references. The team would go into meetings with generic credentials or — worse — miss relevant experience entirely because nobody remembered a project from two years ago.
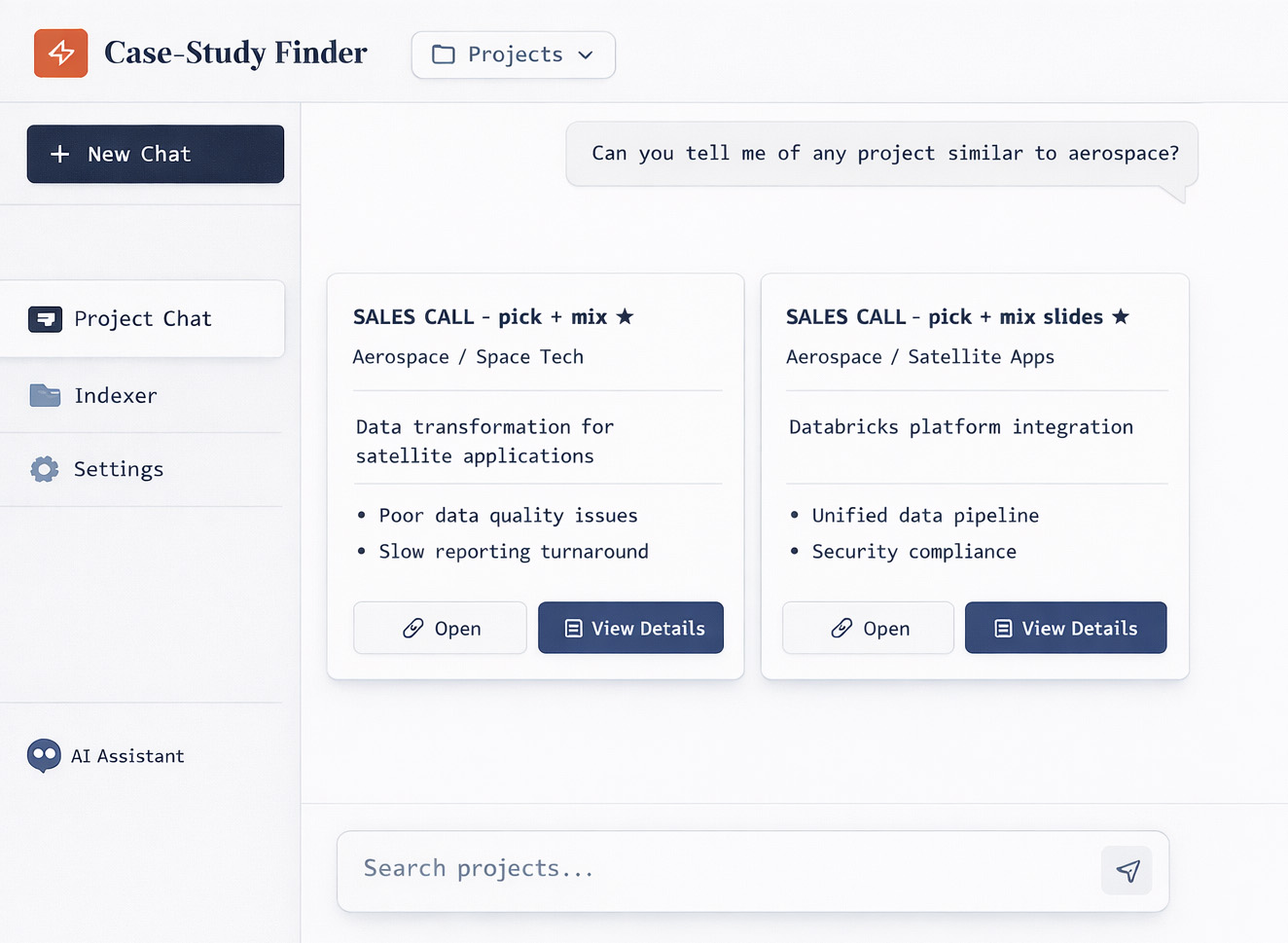
After the tool, a sales rep types a few sentences about the opportunity and gets back the most relevant past projects in minutes. Not a list of document names. Actual matches with context: here’s a project in the same industry, here’s one with a similar challenge, here’s one where the outcome maps to what this prospect is looking for.
The pitch quality went up. The prep time went down. And deals that would have been generic pitches became tailored, evidence-backed proposals that showed the prospect exactly why we’re the right fit.
That’s the difference between “we do data and AI” and “we solved this exact problem for a business like yours 18 months ago — here’s what happened.”
Why This Matters Beyond Sales
This isn’t just a sales tool. It’s a signal of where AI is heading.
The industry spent 2024 and 2025 convinced that RAG was the answer to everything. Embed your documents, build a retrieval pipeline, and you’re done. But the failure rates tell a different story. Most RAG implementations stall between proof of concept and production because the engineering complexity is enormous and the results are brittle.
Agentic approaches flip the model. Instead of pre-processing everything upfront and hoping the retrieval works, you let the AI do what it’s actually good at — reading, reasoning, and making judgements in real time. It’s more flexible, faster to deploy, and far easier to maintain.
For SMEs especially, this matters. You don’t have the engineering team to build and maintain a RAG pipeline. But you do have hundreds of documents full of valuable knowledge that your team can’t access quickly enough.
The question isn’t “should we build a RAG system?” It’s “how do we unlock the knowledge we already have, as fast as possible?”
The Competitive Edge Nobody Sees Coming
Teams with sales enablement tools hit 49% win rates compared to 42.5% without. That gap widens when the enablement isn’t generic — when it’s powered by your actual project history and tailored to each opportunity.
Every past project your company has delivered is a competitive advantage — but only if your team can find it, reference it, and use it in the next pitch. If they can’t, it’s just a PDF sitting in a folder that nobody opens.
The companies that will win more deals in 2026 aren’t necessarily the ones with the best capabilities. They’re the ones who can prove their capabilities fastest — with real examples, real outcomes, and real relevance to the prospect sitting across the table.
Your project history is one of your most valuable sales assets. Start treating it like one.


